
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 쿠버네티스
- Spring
- nGrinder
- ingress
- Adapter 패턴
- 클라우드 네이티브 자바
- MySQL
- CRD
- decorator 패턴
- java
- spring microservice
- 헬름
- 자바
- Algorithm
- 익명클래스
- cloud native java
- Semaphore
- 머신러닝
- kubernetes
- cloud native
- devops
- MSA
- 클라우드 네이티브
- 코틀린
- Microservice
- 동기화
- Stress test
- Kotlin
- ansible
- 마이크로서비스
- Today
- Total
카샤의 만개시기
Preference learning with automated feedback for cache eviction 본문
Preference learning with automated feedback for cache eviction
SKaSha 2023. 7. 8. 07:05서론
IT 전반에 있어 머신러닝을 이용한 효율화에 대한 고찰들이 이루어지고 있으며
강화학습을 이용한 정렬 알고리즘 뿐만 아니라 Cache를 효율적으로 사용함에 있어서도 이러한 고민들이 이루어지고 있다.
캐시는 컴퓨터 과학에서 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다.
캐시는 캐시의 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용한다.
캐시에 데이터를 미리 복사해 놓으면 계산이나 접근 시간없이 더 빠른 속도로 데이터에 접근할 수 있다.
기존에 우리는 캐시를 효율적으로 사용하기 위하여 Cache Eviction 알고리즘을 도메인에 맞게 선택하여 사용해왔다.
Cache Eviction Algorithms
- First-In-First-Out (FIFO) Algorithm
- Least Recently Used (LRU) Algorithm
- Least Frequently Used (LFU) Algorithm
- Random Replacement (RR) Algorithm
- Clock (Second-Chance) Algorithm
- Adaptive Replacement Cache (ARC) Algorithm
HALP
Heuristic Aided Learned Preference Eviction Policy for
YouTube Content Delivery Network
HALP는 무작위화를 사용하여 가벼운 휴리스틱 기준 축출 규칙을 학습된 보상 모델과 병합하는 meta-algorithm 이다.
이는 선호도 비교를 통해 지속적인 자동 피드백으로 훈련되는 경량 신경망입니다.
구글에서는 이 알고리즘을 통해 YouTube의 CDN 인프라 효율성과 사용자 비디오 재생 대기 시간을 개선하였습니다.
HALP는 아래와 같은 두가지 요소를 통하여 캐시 제거 결정을 계산합니다.
- preference learning을 통해 자동화 된 피드백으로 훈련된 신경 보상 모델
- 학습된 보상 모델을 빠른 휴리스틱과 결합하는 메타 알고리즘
캐시에 들어오는 요청을 선호도 피드백을 통하여 학습하는 방식은 인간 피드백 방식의 강화학습과 관점이 비슷하지만 다음과 같은 차이점이 있습니다.
- 피드백은 자동화되고 오프라인 최적 캐시 제거 정책의 구조에 대해 잘 알려진 결과를 활용
- 모델은 자동화된 피드백 프로세스에서 구성된 훈련 예제의 임시 버퍼를 사용하여 지속적으로 학습
캐시 삭제 정책은 다음과 같은 절차로 진행됩니다.
- 성능적으로 차선책이면서 효율적인 휴리스틱을 통하여 후보자를 선별합니다.
- re-ranking 단계를 통하여 인공 신경망은 후보군 사이에서 선별 결과를 최적화 합니다.
HALP는 캐시 삭제 결정을 내릴 뿐만 아니라 관련 피드백을 효율적으로 구성하고 모델을 업데이트하여 후보자를 선별하는 결정을 강화하는 종단 간 프로세스를 포함합니다.
A neural reward model
HALP는 경량화 된 다층 퍼셉트론으로 구성되어 있습니다.
그리고 가중치는 무작위로 초기화 된 값에서 시작하여 완전히 온라인으로 보상 모델을 학습합니다.
HALP는 보상 모델이 완전히 일반화되었을 때 최적의 성능을 제공하지만,
아직 일반화되지 않았거나 변화하는 환경을 따라잡는 과정에서는 LRU와 같은 차선이지만 강력한 휴리스틱에 의존함으로써 강인함을 유지합니다.
온라인 학습의 또다른 강점은 전문화(specialization)입니다.
각 캐시 서버는 잠재적으로 다른 환경(예: 지리적 위치)에서 실행되므로 해당 환경에 맞는 조건이나 인기 있는 콘텐츠에 영향을 미치므로 일반화의 부담이 적습니다.
Scoring samples from a randomized priority queue
배타적으로 학습된 모델로 eviction 결정 품질을 최적화하는 것은 두 가지 이유로 비실용적일 수 있습니다.
- 컴퓨팅 효율성 제약 조건: 학습된 모델을 사용한 추론은 대규모로 작동하는 실제 캐시 정책에서 수행되는 계산보다 훨씬 더 큰 비용일 수 있습니다.
- 분포 외 일반화를 위한 강건성(Robustness): HALP 모델은 계속된 학습 내용이 반영되는데, 빠르게 변하는 워크로드에서는 학습된 과거 데이터에 의존하여 일시적으로 분포 외 결과 값을 낼 수 있습니다.
이러한 문제를 해결하기 위해 HALP는 먼저 제거 우선 순위에 해당하는 저렴한 휴리스틱 점수 규칙을 적용하여 작은 후보 샘플을 식별합니다.
Online preference learning with automated feedback
보상 모델은 온라인 피드백을 사용하여 학습됩니다.
이는 향후 re-access 요청을 수신하는 데까지 걸리는 시간에 대해 자동 할당된 선호도 레이블을 기반으로 합니다.
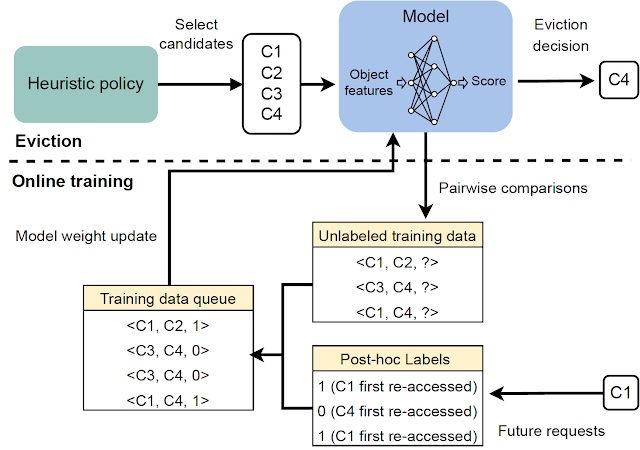
피드백 프로세스를 유익하게 만들기 위해 HALP는 eviction 결정과 관련이 있을 가능성이 가장 높은 Pairwise 선호 쿼리를 구성합니다.
Results: Impact on the YouTube CDN
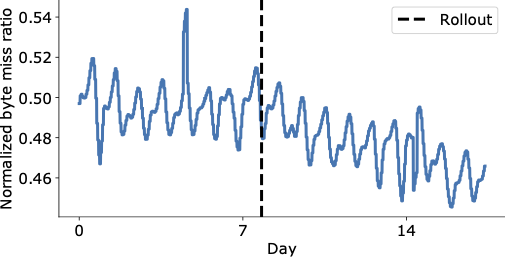
HALP를 rollout 하기 전과 후의 캐시 miss ratio를 비교해볼수 있었다.
Conclusion
HALP는 레이블이 지정된 예제, 학습 절차 및 모델 버전을 대부분의 기계 학습 시스템에 공통적인 추가 오프라인 파이프라인으로 별도로 관리해야 하는 운영 오버헤드 없이 다른 캐시 정책과 유사한 방식으로 적용할 수 있었다.
따라서 다른 기존 알고리즘에 비해 약간의 추가 오버헤드가 발생하지만 추가적인 feature를 활용하여 캐시 제거 결정을 내리고 변화하는 액세스 패턴에 지속적으로 적응할 수 있는 추가 이점을 얻을 수 있었다.
참고
https://ai.googleblog.com/2023/06/preference-learning-with-automated.html
'Machine Learning' 카테고리의 다른 글
| 머신러닝 모델의 성능 평가 지표 (0) | 2020.01.20 |
|---|---|
| 그리드 서치를 이용한 하이퍼파라미터 튜닝 (0) | 2020.01.20 |
| 머신러닝 모델 성능 평가 (홀드아웃 및 k-겹 교차 검증) (2) | 2020.01.20 |
| sklearn Pipeline 파이프라인 (0) | 2020.01.20 |
| 가중치를 0으로 초기화 하지 않는 이유 (0) | 2020.01.18 |



